How Data Flows to the Blockchain
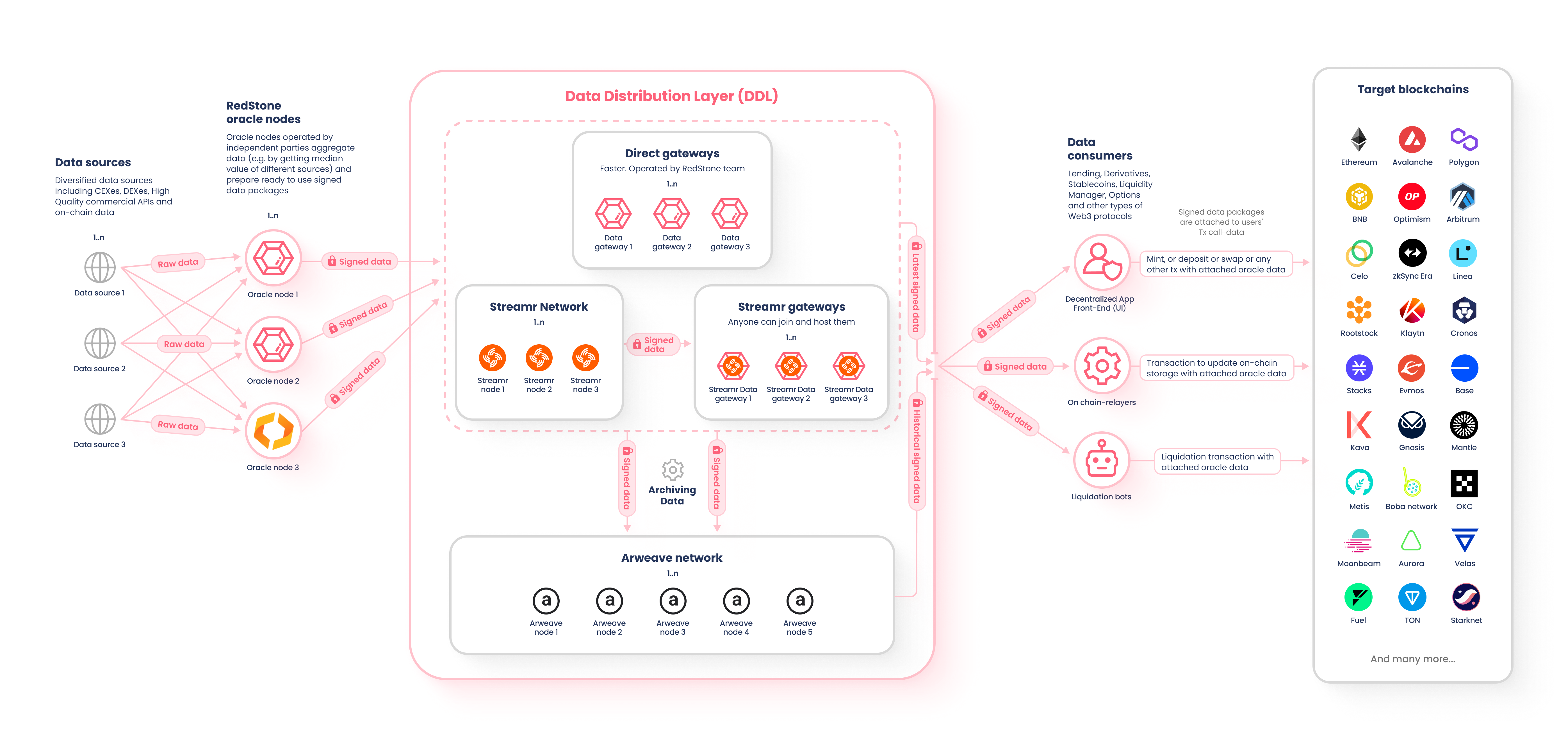
Overview
The price feeds provided to RedStone’s clients come from a diverse range of sources. This includes exchanges like Binance and Coinbase, decentralized exchanges (DEXs) like Uniswap and Sushiswap, and price aggregators like CoinMarketCap and CoinGecko. RedStone has over 150 sources integrated to date. The data is aggregated by independent nodes operated by data providers using various methodologies. Some methods include median, TWAP, and LWAP, which are all designed to capture the most accurate price by considering factors like the amount of liquidity available, and the average price during specific timeframes.
Additionally, data-quality measures are implemented like detecting unexpected values (outlier detection), to ensure the data is correct. Afterward, the cleaned and processed data is then signed by node operators underwriting its quality. The feeds are broadcasted both on the Streamr, a decentralized data network, and directly to open-source gateways which could be easily spun-off when necessary. The data could be pushed onto the blockchain either by a dedicated relayer operating under predefined conditions, like a specific change in price, by a bot (ie. performing liquidations), or even by end users interacting with the protocol. Inside the protocol, the data is unpacked and verified cryptographically confirming both the origin and timestamps.
Data Formatting & Processing
Context
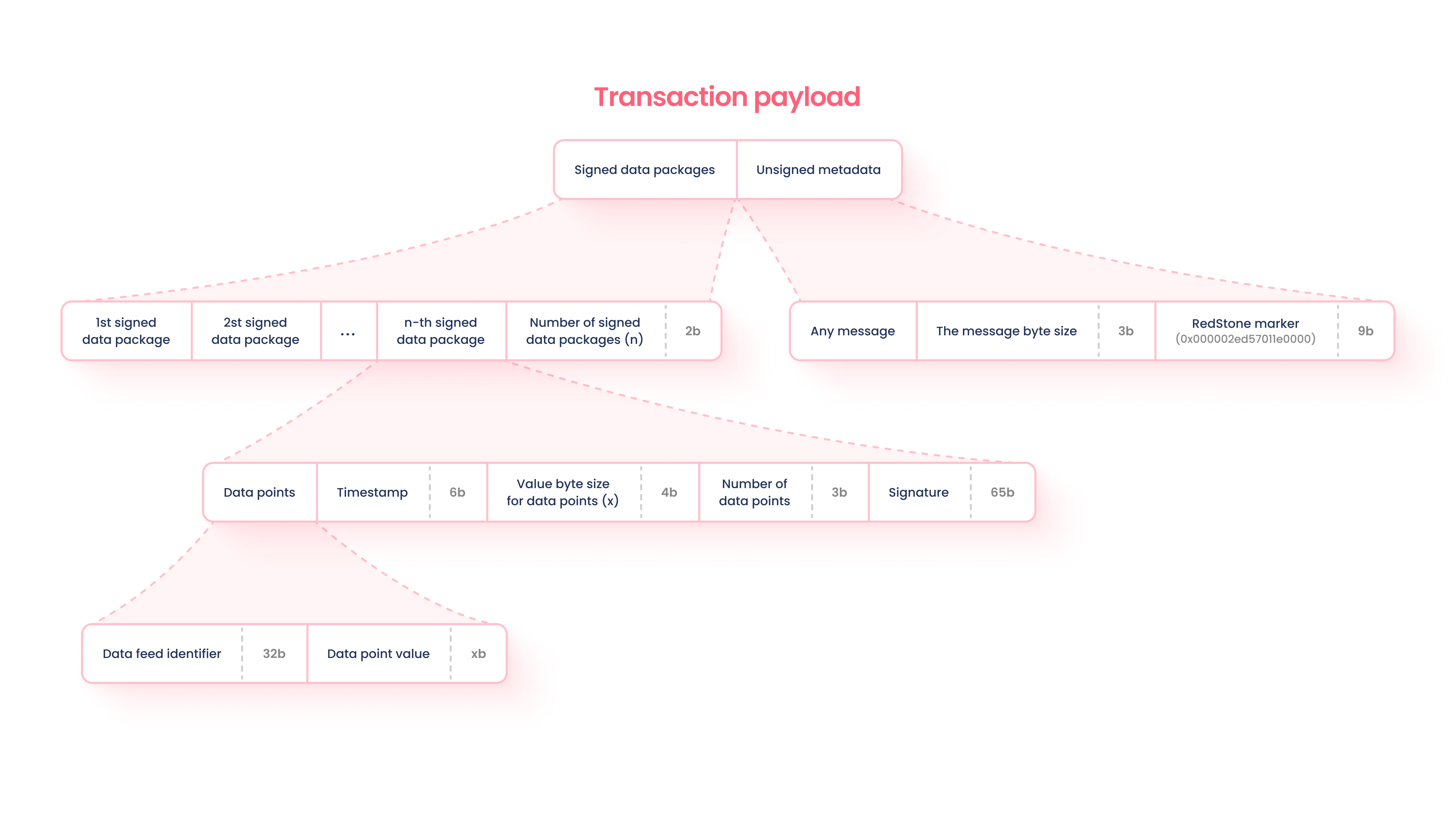
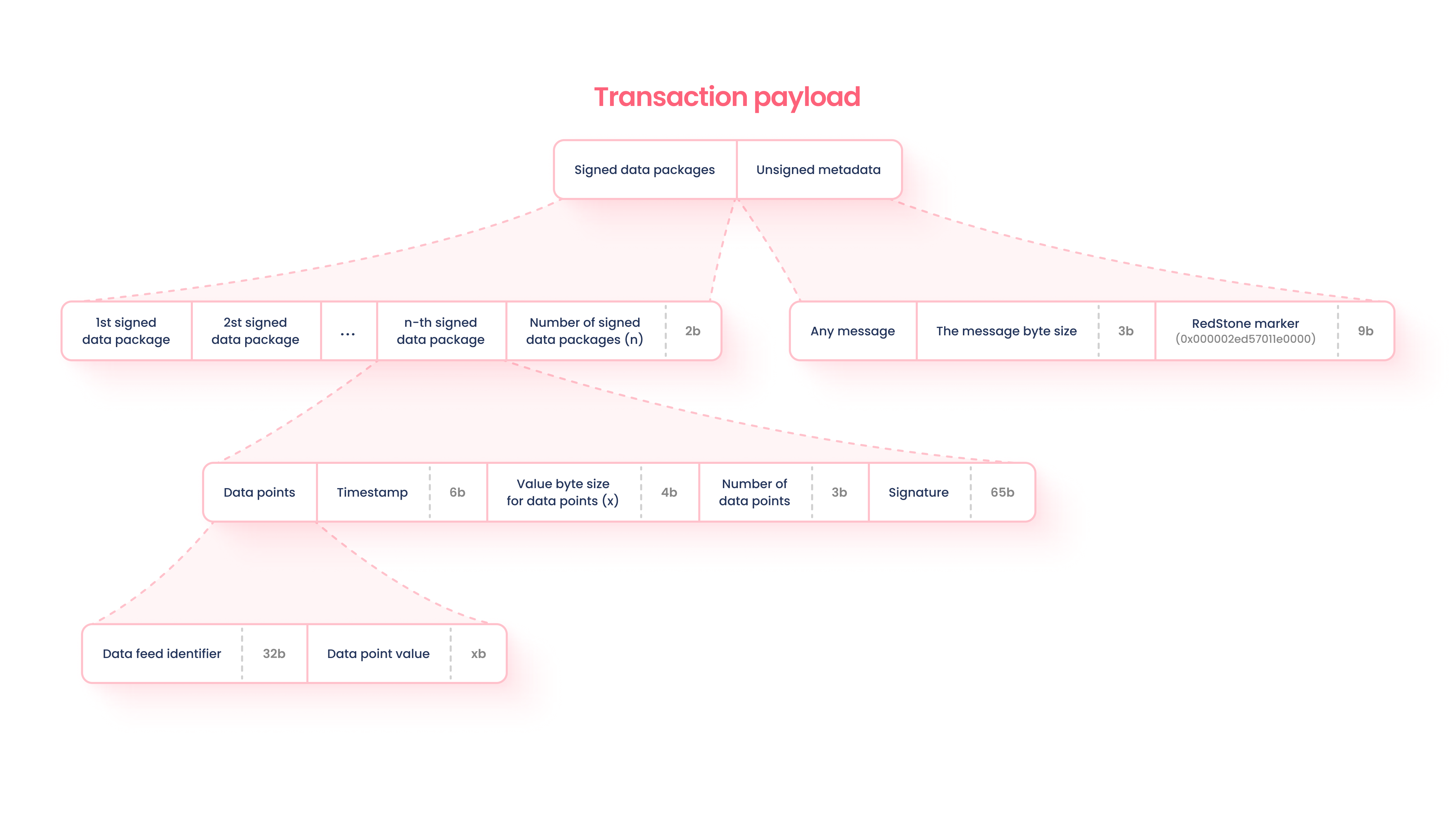
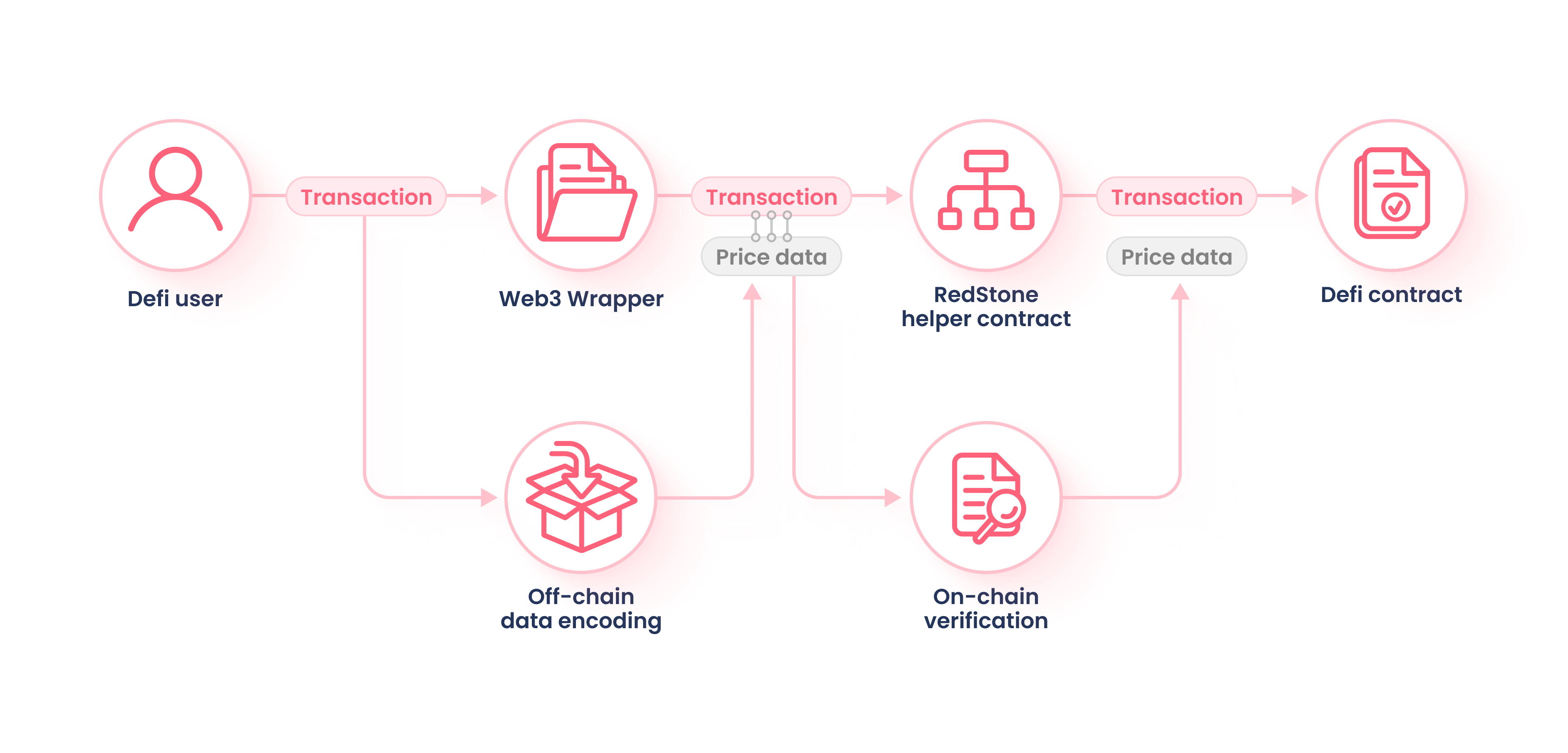
Transferring data to a blockchain requires packing an extra payload to a user’s transaction and processing the message on the blockchain. Said differently, the data that is put on the blockchain, such as a cryptocurrency’s price, is inserted into part of the data that makes up a user’s transaction. This is accomplishable because blockchains move from state-to-state and contain call data. RedStone is able insert its data into the call data of a user's transaction, thereby putting the data onto the blockchain.
How Data is Encoded Before Being Put on the Blockchain
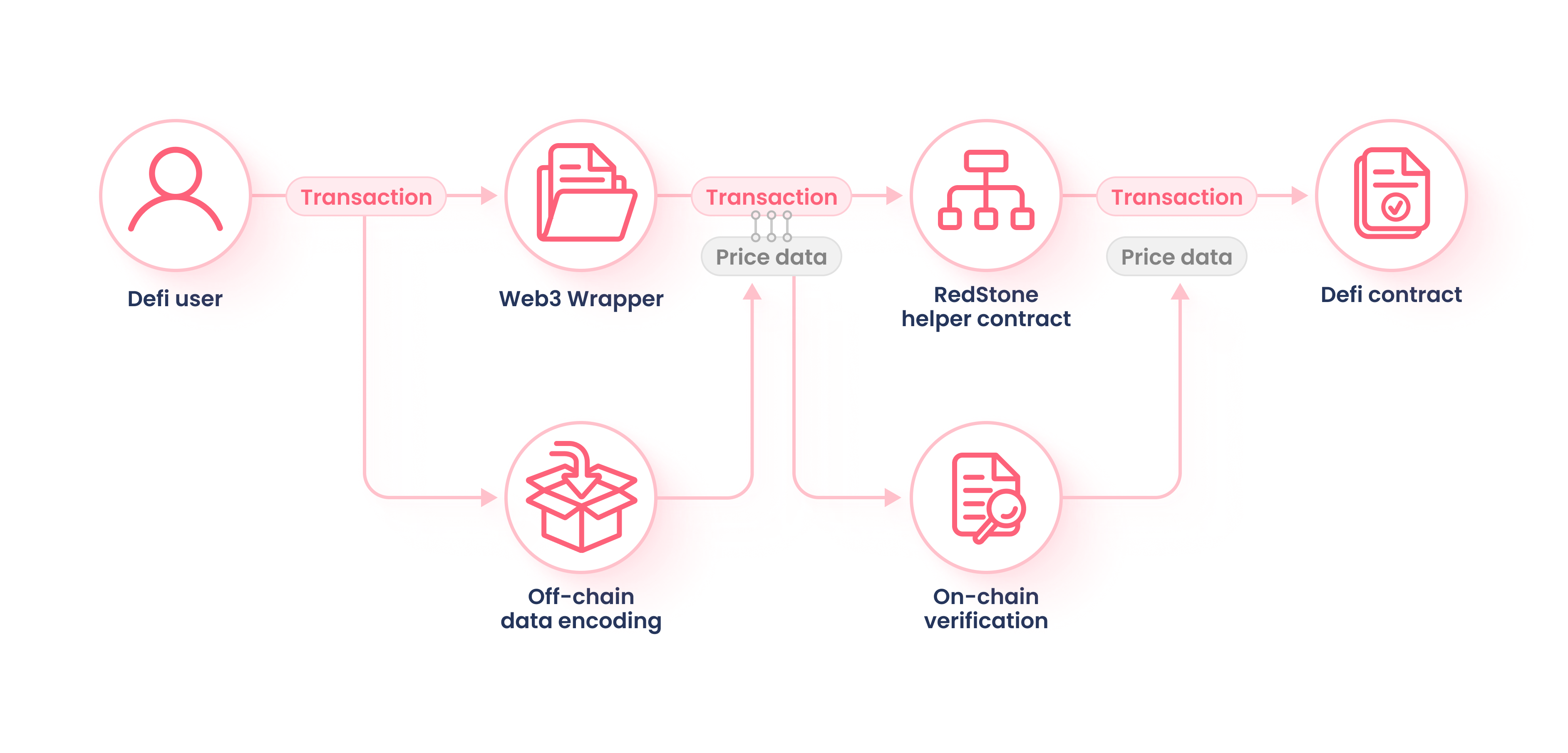
All of the steps are executed automatically by the ContractWrapper and is transparent to the end-user_
-
Relevant data must be fetched from the data distribution layer, powered by the Streamr network or the RedStone gateways.
-
Data is packed into a message based on the structure of the ‘Transaction Payload’ diagram below…
-
The package is appended to the original transaction message, signed, and submitted to the network.
How Data Is Unpacked, Verified and Then Aggregated On-Chain
Firstly, the appended data packages are extracted from the call data. Then, security steps are taken including verifying if the signature was created by a trusted provider and validating the timestamp, confirming the information is correct. Afterward, for each requested data feed RedStone calculates the number of received unique signers, extracts the value for each unique signer, and calculates the aggregated value. The middle value of all the values (median), is the default value that is provided. This logic is executed in the on-chain environment and its execution has been optimized using a low-level assembly code to reduce gas consumption to the absolute minimum. To increase the security of the RedStone Oracle system, we've created the on-chain aggregation mechanism. This mechanism adds an additional requirement of ensuring a minimum number of distinct data feeds are relied on. The values from different providers are then aggregated before returning to a consumer contract. By default, RedStone uses the median value calculation for aggregation. This way, even if a small subset of providers are corrupt (e.g. 2 of 10), it does not significantly affect the aggregated value.
Technical Considerations When Implementing RedStone's Data Feeds
On-Chain Aggregation Parameters in RedStone’s Consumer Base Contract
getUniqueSignersThreshold function
Purpose: Determines the threshold number of unique signers required to validate a piece of data. RedStone relies on multiple independent signers to ensure its accuracy and integrity.
getAuthorisedSignerIndex function
Purpose: Returns the index of an authorized signer from a list of signers. It is used to verify if a given signer is authorized to sign data.
aggregateValues function (for numeric values)
Purpose: Aggregates numeric values from multiple data points. It could calculate an average like the median. Aggregating values from multiple sources helps in reducing the impact of any single erroneous data point.
aggregateByteValues function (for bytes arrays)
Purpose: Aggregates values specifically for byte arrays.
Types of Values Supported
We support 2 types of data to be received in a contract:
- Numeric 256-bit values (used by default)
- Bytes arrays with dynamic size
Security Considerations
-
Overriding
getUniqueSignersThresholdmay be a significant risk. We only recommend overriding it if you are 100% confident. -
Pay attention to the timestamp validation logic. For some use-cases (e.g. synthetic DEX), you would need to cache the latest values in your contract storage to avoid arbitrage attacks.
-
Enable a secure upgradability mechanism for your contract (ideally based on multi-sig or DAO).
-
Monitor the RedStone data services registry and quickly modify signer authorization logic in your contracts in case of changes (we will also notify you if you are a paying client).
Recommendations
- Write smart contracts in a way where you do not need to request many data feeds in the same transaction.
- Approximately 3 required unique signers is our recommended balance to be secure and minimize gas costs.
Benchmarks
You can check the benchmarks script and reports here.